

- cross-posted to:
- programming
- cross-posted to:
- programming
This is an excellent overview of tokenization with many interesting examples. I also like Simon’s small CLI tools; you can read about them at the end of the post.
As usual, I’ve asked GPT-4 to write a TL;DR and detailed notes for it.
Notice that it couldn’t print the “davidjl” glitch token, and (probably because of its presence), the notes are also incomplete. At first I thought it was because the text of the article was longer than the context window, but the TL;DR contains details the notes don’t so that probably wasn’t the case.
I’ve still decided to copy the notes here because they are generally useful and also demonstrate this weird behavior.
TL;DR (by GPT-4 🤖)
The article discusses the concept of tokenization in large language models like GPT-3/4, LLaMA, and PaLM. These models convert text into tokens (integers) and predict the next tokens. The author explains how English words are usually assigned a single token, while non-English languages often have less efficient tokenization. The article also explores “glitch tokens,” which exhibit unusual behavior, and the necessity of counting tokens to ensure OpenAI’s models’ token limit is not exceeded. The author introduces a Python library called tiktoken and a command-line tool called ttok for this purpose. Understanding tokens can help make sense of how GPT tools generate text.
Notes (by GPT-4 🤖)
Understanding GPT Tokenizers
- Large language models like GPT-3/4, LLaMA, and PaLM operate in terms of tokens, which are integers representing text. They convert text into tokens and predict the next tokens.
- OpenAI provides a Tokenizer tool for exploring how tokens work. The author has also built a tool as an Observable notebook.
- The notebook can convert text to tokens, tokens to text, and run searches against the full token table.
Tokenization Examples
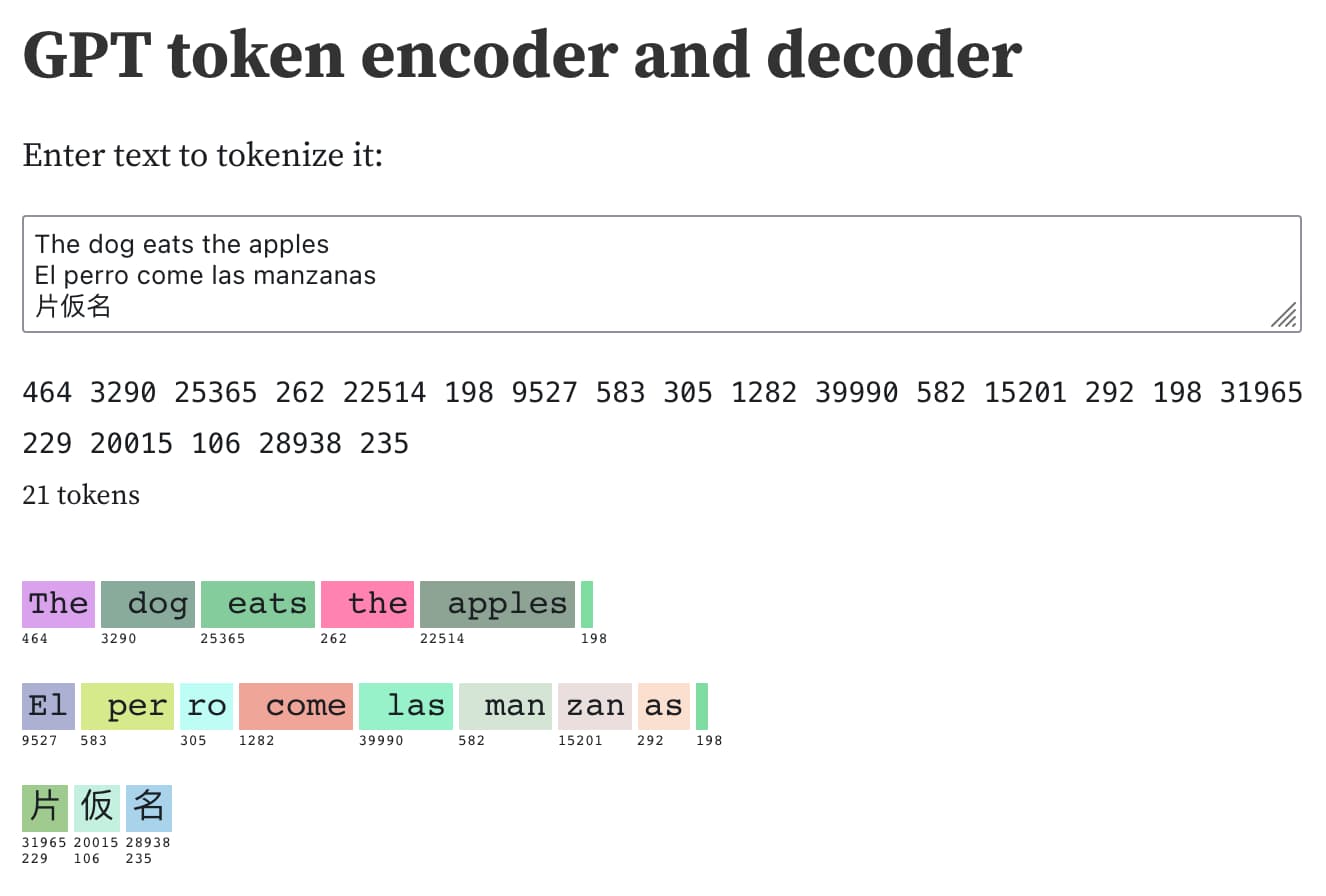
- English words are usually assigned a single token. For example, “The” is token 464, " dog" is token 3290, and " eats" is token 25365.
- Capitalization and leading spaces are important in tokenization. For instance, “The” with a capital T is token 464, but " the" with a leading space and a lowercase t is token 262.
- Languages other than English often have less efficient tokenization. For example, the Spanish sentence “El perro come las manzanas” is encoded into seven tokens, while the English equivalent “The dog eats the apples” is encoded into five tokens.
- Some languages may have single characters that encode to multiple tokens, such as certain Japanese characters.
Glitch Tokens and Token Counting
- There are “glitch tokens” that exhibit unusual behavior. For example, token 23282—“djl”—is one such glitch token. It’s speculated that this token refers to a Reddit user who posted incremented numbers hundreds of thousands of times, and this username ended up getting its own token in the training data.
- OpenAI’s models have a token limit, and it’s sometimes necessary to count the number of tokens in a string before passing it to the API to ensure the limit is not exceeded. OpenAI provides a Python library called tiktoken for this purpose.
- The author also introduces a command-line tool called ttok, which can count tokens in text and truncate text down to a specified number of tokens.
Token Generation
- Understanding tokens can help make sense of how GPT tools generate text. For example, names not in the dictionary, like “Pelly”, take multiple tokens, but “Captain Gulliver” outputs the token “Captain” as a single chunk.
AFAIK the way it works is that the more frequent a long sequence is, the more likely it is to get a single token. I’m not sure the fact that English is tokenized in the most efficient way is because they explicitly made it prefer English or if it is just a result of the corpus containing mostly English text.