
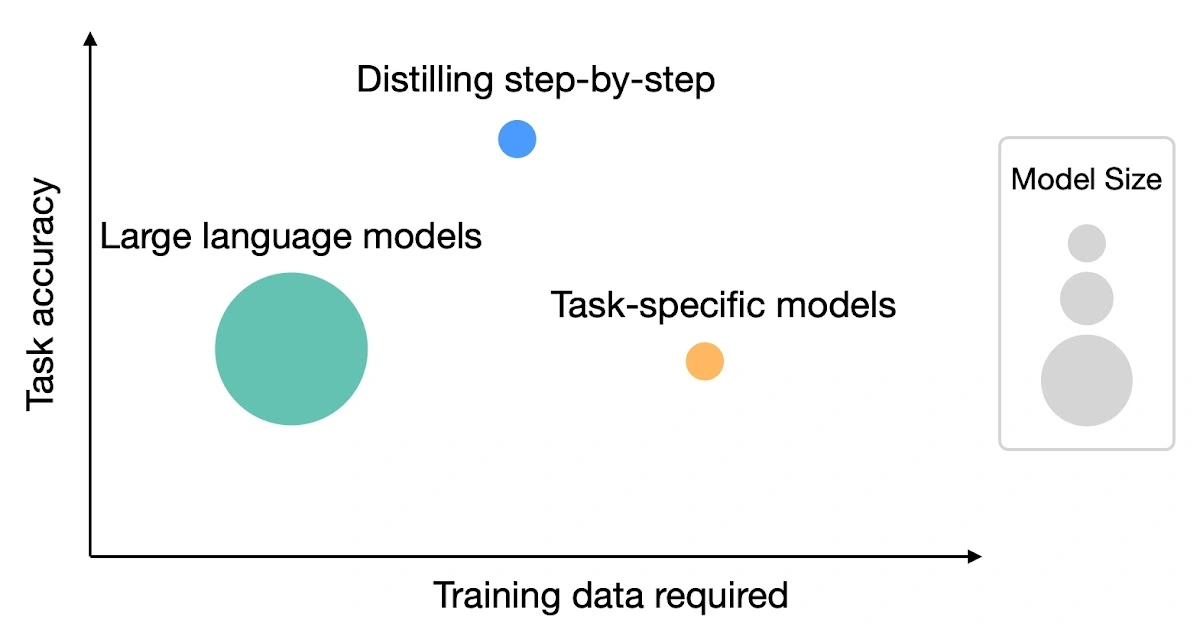
Large language models (LLMs) are data-efficient but their size makes them difficult to deploy in real-world scenarios.
“Distilling Step-by-Step” is a new method introduced by Google researchers that enables smaller models to outperform LLMs using less training data. This method extracts natural language rationales from LLMs, which provide intermediate reasoning steps, and uses these rationales to train smaller models more efficiently.
In experiments, the distilling step-by-step method consistently outperformed LLMs and standard training approaches, offering both reduced model size and reduced training data requirements.
You must log in or register to comment.