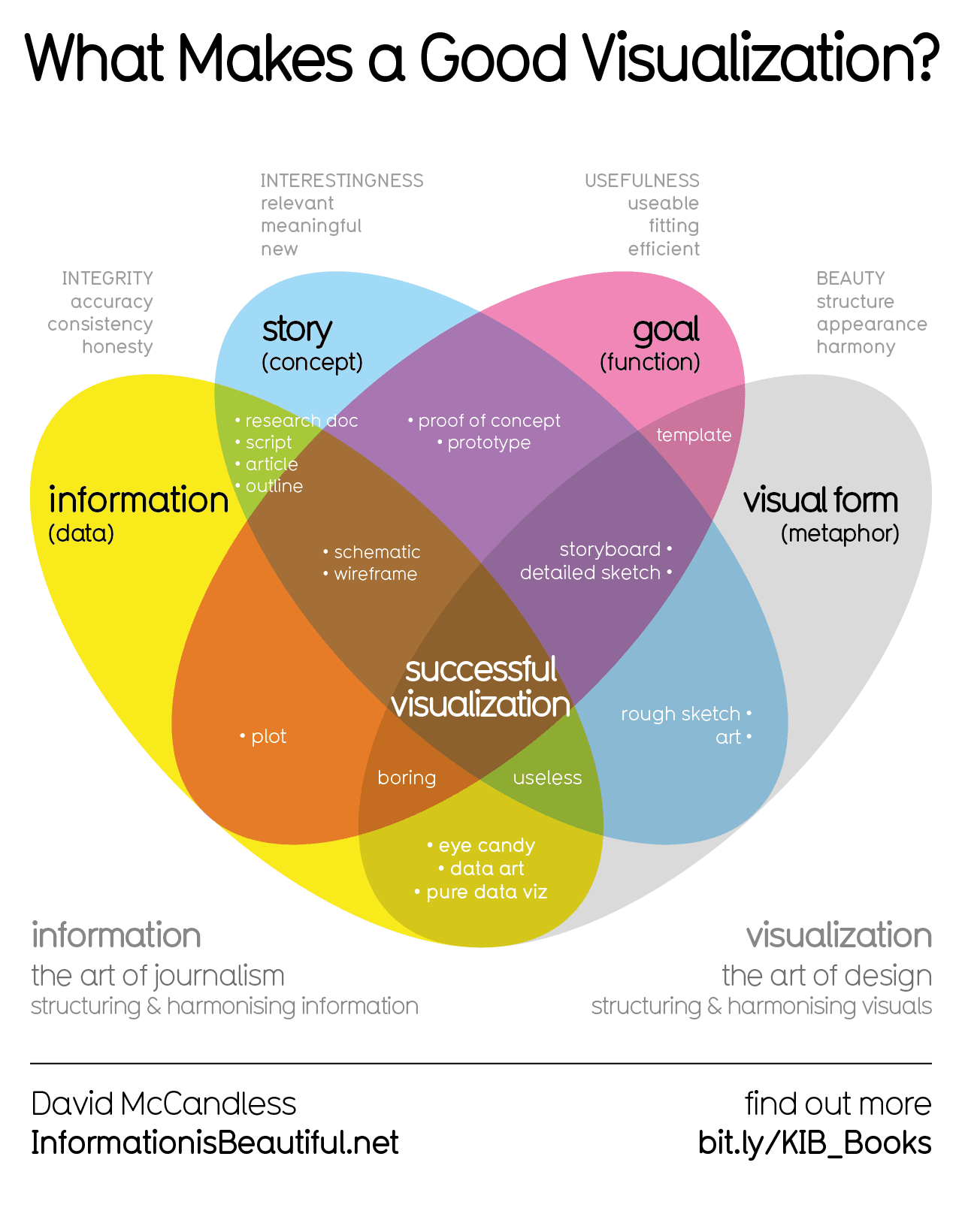
cm0002@lemmings.world to Data is Beautiful@mander.xyzEnglish · 1 month agoContradictions in the Biblelemmy.mlimagemessage-square75linkfedilinkarrow-up1400arrow-down136cross-posted to: [email protected]
arrow-up1364arrow-down1imageContradictions in the Biblelemmy.mlcm0002@lemmings.world to Data is Beautiful@mander.xyzEnglish · 1 month agomessage-square75linkfedilinkcross-posted to: [email protected]
minus-squarelolola@lemmy.blahaj.zonelinkfedilinkEnglisharrow-up13arrow-down4·1 month agoThis “beautiful” dataset contains duplicate entries (#7 and 9). There may be others, stopped reading after that.
minus-squarewhoever loves Digit 🇵🇸🇺🇸🏴☠️@piefed.sociallinkfedilinkEnglisharrow-up1·1 month agoThank you for the due diligence, I almost cross posted this unknowingly
minus-squareFaceDeer@fedia.iolinkfedilinkarrow-up1arrow-down3·1 month agoThe text at the bottom has duplicates, sure. Do you think that’s the “beautiful” part?
minus-squarelolola@lemmy.blahaj.zonelinkfedilinkEnglisharrow-up9arrow-down3·1 month agoI think a beautiful dataset wouldn’t have a duplicate entry in the first ten rows.
minus-squareFaceDeer@fedia.iolinkfedilinkarrow-up4arrow-down2·1 month agoThe duplication would result in an arc being drawn twice with exactly the same pixels. Ie, it would make no difference whatsoever to the display. It has no effect on the “beauty” part. You might as well be objecting to the font that the text is in.
minus-squarelolola@lemmy.blahaj.zonelinkfedilinkEnglisharrow-up3arrow-down1·1 month agoFont choice is also a factor in data visualization hehe
minus-squareFaceDeer@fedia.iolinkfedilinkarrow-up2arrow-down1·1 month agoYou could literally chop the lower half of this image off and it would make no difference to the data visualization.
minus-squarelolola@lemmy.blahaj.zonelinkfedilinkEnglisharrow-up4·1 month agoI’d say it’d be an improvement because I wouldn’t have been distracted by this little mistake lol I’m a data scientist and a nitpicker, not in that order.
{kind=link}
This “beautiful” dataset contains duplicate entries (#7 and 9). There may be others, stopped reading after that.
Thank you for the due diligence, I almost cross posted this unknowingly
The text at the bottom has duplicates, sure. Do you think that’s the “beautiful” part?
I think a beautiful dataset wouldn’t have a duplicate entry in the first ten rows.
The duplication would result in an arc being drawn twice with exactly the same pixels. Ie, it would make no difference whatsoever to the display. It has no effect on the “beauty” part. You might as well be objecting to the font that the text is in.
Font choice is also a factor in data visualization hehe
You could literally chop the lower half of this image off and it would make no difference to the data visualization.
I’d say it’d be an improvement because I wouldn’t have been distracted by this little mistake lol
I’m a data scientist and a nitpicker, not in that order.