

Hello everyone!
TL;DR: I want to propose a community-driven effort to research and improve 1-bit LLM models, for use within and outside the Horde. I think having access to such models would be very useful for the overall project, as you do not need a lot of compute to run “bigger” models if they’re compressed well. Relevant paper.
We currently live in very interesting times regarding AI development. The big companies in the US seem to still be ahead, but groups from China, working on open-weights models, are making very impressive strides. However, the focus has been and still is on developing really big models. Most of the impressive models that keep coming out are bigger and bigger, leaving most people to pay for API tokens if they want something useful. Probably this is also incentivised, as Nvidia wants to make more money from sales to data centers.
I have been keeping an eye out for the AI Horde project, and I always wanted to help out, but never got around to setting it properly up due to my AMD GPU and running Windows. However, really cool project, and I wanted to congratulate everyone involved!
In my opinion, the goal of the AI Horde community also positions it as one of the very few that are capable of bringing forward some LLMs that can be “smart” on consumer-level hardware. That is, getting models that can handle long-horizon tasks well without paying providers for API access.
Since the first paper on 1.68-bit LLMs, there has been quite a few other suggestions thrown around (recent example). No one really uses these models much, as the quality is seriously degraded. Similarly, no one is really trying to improve these models further, as there is no incentive to do so when you can just pay someone 3$ per million token output from an existing open-weight model. For example, to the best of my knowledge, no one has tried to introduce latent reasoning (example) in this context, or specifically training/fine-tuning models at 1-bit levels.
So, to get to the point, would it make sense to get some community-driven research in this area? I believe that we could all pool together compute, good training data, ideas for fine-tuning / RL-training, etc. If it works out, we could have a method that makes existing larger models (say, up to 200B) available on a single 24GB GPU.
First thing I would try is to expand on the recent NanoQuant paper:
- Wait for weights to be released.
- If no weights come out, quantize a Qwen 3 32B, and try a more diverse dataset, with more tokens to see if fidelity can improve. I could get some access to GPUs for this myself. Another option for 1-bit models would be using other existing ones (e.g., Unsloth), but performance degradation is much bigger in those versions, from what I have seen. Furthermore, the compression of these models is not as efficient, and you would not be able to fully run a 70B parameter (as described in the paper), with only 8GB VRAM.
- Get an LLM (or human volunteers) to determine behaviour on various tasks: find limitations, strengths, etc. Get some human preferences for RLHF, or use a bigger LLM to grade output quality. Preference here on logic tasks.
- Perform fine-tuning of 1-bit model based on the gathered data, and deploy for use. Return to step 2 after a while.
Fine-tuning the 1-bit model might get a bit hairy, as the binary operation are not differentiable. We also wouldn’t be able to up-cast back to F32 for regular training, as this would completely invalidate the consumer-driven access to these models. Simplest idea would be to train a LoRA head, or do some stochastic-driven training (e.g., flipping bits). However, the latter would probably be very unstable, and not work out, and LoRA might be the only option. I’m not a mathematician, so I am open to suggestions here :)
Past the initial prototype, I would consider the following stuff that’s already implemented in other quants:
- Try to re-calibrate the LayerNorm / RMSNorm parameters based on the original model’s activations.
- Perform some regular KL-divergence distillation
- Other than using an LLM as a judge for RL, perhaps one could also fine-tune using a semantic similarity metric while aligning with the output of the original model. This could ensure that the intent is the same, even if the style differs.
- Depending on token complexity, look into reducing compression just for difficult tokens and compressing further for easy ones (à la FlexQuant)
- Mixture-of-Experts-style quantization, where we increase compression for experts that are not important, and reduce it for higher-frequency ones.
Curious what everyone thinks!
The models themselves would indeed be costly to train if you were to go for the regular approach. You would have to “upscale” the weights to be fp32 from binary, which would make the models only trainable on the usual amount of GPUs. That is because the training process relies on back-propagation, which only makes sense if your operations are differentiable. Since addition is not differentiable, your binary weights would only be updated by 0, so no change.
However, LoRA (16-bit) QLoRA (4/8-bit) fine-tuning can be done on a single GPU, assuming you can fit the model on it. Everything is frozen, except for a separate small network, which is updated during training. This can have BF16 or F32 precision, and would be trained as you would a regular network.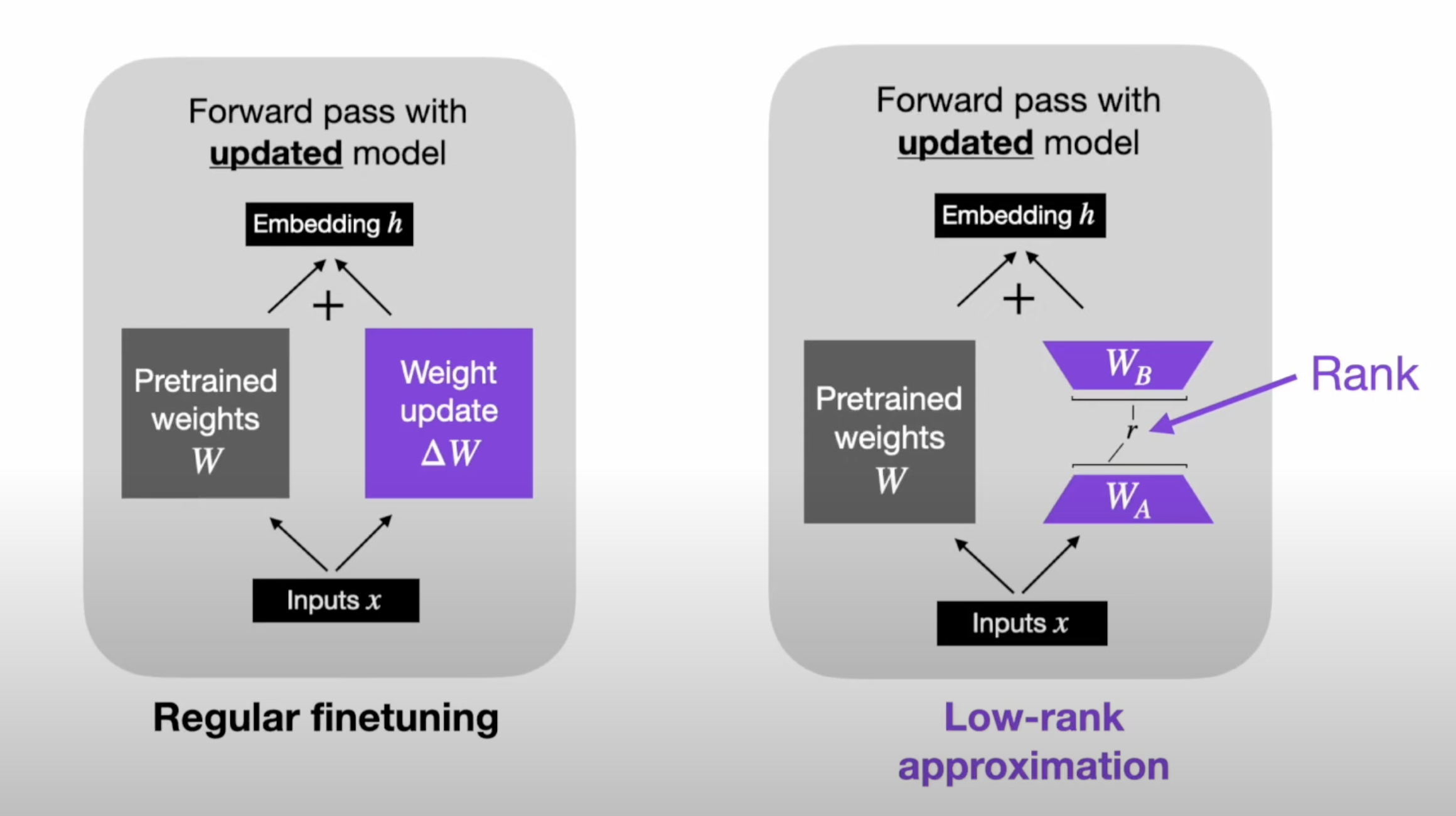
What I am suggesting is to actually leverage bigger models that come out, and attempt to compress them using the proposed algorithm (if it actually scales to bigger models). From there, we could employ some tricks to improve performance, think latent reasoning, community-driven RLHF only on the (Q)LoRA layers, etc. With time, we would be able to pool together a dataset and a pipeline that can be applied to any open-weight model that is released.
But it does sound a bit easier than it would be in practice. This heavily relies on re-purposing the Horde to also store training data (with user consent, of course), user scores, and later introduce a training queue.
Sure. I mean I know we can do it for 4bit or 8bit quantizations. Question is just if it can be done for 1bit. As per Microsoft’s first Bitnet paper, the answer was a clear: No. Seems I’ve missed the NanoQuant paper from a few days ago. They did post-training quantization. But the numbers don’t look impressive to me? I mean I’m not an expert and have just skimmed it. But the benchmarks in table 3 look like some very old model from a few years ago. Every tiny modern model can reach better scores. And the perplexity in table 2 doesn’t look great to me either. Sure, you could run a 1-bit version of a 70b parameter model… But that’s just worse than a 1b parameter model. So you can probably just skip the entire effort with the 1-bit quantization, download the smallest variant there is, run it straight out of the box, and it’d be both more “intelligent” and at least 4x faster.
I mean ultimately, you’re right. I’d like to know the benchmark results for something like a 70b model. Seems they only list those for small models. And it’s a shame they didn’t release any weights.
But I don’t see why we need a collaborative Horde effort to find out… They write a 70b model can be compressed on an H100 in 13 hours. And for example runpod.io charges $2.39 per hour for such an instance. So all we need is a bit more than $30 to find out?!
Indeed, the quantization described in the Microsoft paper (and even in this NanoQuant paper) severely messes up the behaviour of the model. Even in this newer paper, you’d still incur ~2x performance loss (which is better than what was reported by 1.68 bit paper, if true), in terms of perplexity. However, as per the other paper I have added in the edited post, it is possible to further align a quantized model with the original one. In the end, LLMs are just fancy math that seek to maximize human preferences, and most of the bigger models were just better trained at doing that. With this approach, all we would have to do is just further refine the LoRA weights until we can match the behaviour of the unquantized model, which wouldn’t be that expensive if all we have to do is fine-tune a few million parameters. It might be that at the beginning we’re seeing worse performance compared to a 3B parameter model, but with more refinement we can further unlock some of the original performance.
Regarding the use of the Horde, I believe that behaviour alignment can’t be done without actually using it. Just like corpo-AI are giving away their models so that they can further get data, we could have a similar, but much more compute-efficient, community-driven approach. Models by the people, for the people, if you will. Furthermore, as I mentioned, I think this would be the only community that has the compute and desire to push improvements on such an idea long-term, as it isn’t profit-driven.
Let’s say that this whole experiment starts with an extreme case, the MiniMax M2.5 model, and we abstract away from any architectural fancy stuff. At ~230B parameters, we would have a 1-bit model size of ~28.75 GB, and, as per Table 2 of NanoQuant, ~23 GB if we were to prune 20% of the weights. This would be enough to fully fit it on a 24GB VRAM GPU. Following this, we could get a well-balanced list (i.e., easy, medium, hard) of reasoning tasks, and fine-tune the LoRA layer to match the output. Heck, we could even tailor this to specific tasks, such as role-playing, coding, etc. It will be a long-term experiment where we might serve two answers (depending on Horde availability), one generated by the quantized model + LoRA and another that is regularly deployed. The user could then choose the model they prefer, and use that information later for further training.
This would indeed be quite cumbersome to set up, and could very well be wasted time. Users might even opt out from this because it could take too much time to help. But hey, I still think it would be a cool experiment to see if consumers could actually use these larger models on regular hardware, and get close to the original performance without paying for all the compute that is needed.
Indeed. That looks nice. It’s about 2bit quantization. So not sure if it translates to the other paper. I had a quick glance at their code, and it’s specific to the Llama2 and Llama3 architectures. So, it’d need to be enhanced for other models. And what might be a bummer: they load the model at full precision to calculate the activations. That means you’re looking at a system with ~480GB of (V)RAM. And we don’t have machines of that size show up on the AI horde. (As far as I know.)
I think we’re looking more at crowdfunding research here. I mean sorry for being overly negative. I’d like to see 1bit models as well. And I always love to see community projects and independent people push the limits. I just think the hard part is coming up with the research, the math… or even the engineering to combine two papers and adapt an approach to something. So we somehow need to crowdfund that.
In these two examples, seems the compute power isn’t really the issue. I mean the 1bit training was doable on a single H100. And this LoRa isn’t very complex either, and they’re not using that many samples.
It just wouldn’t fit on any of the 38 LLM workers currently online on the AI Horde. Not even remotely. So this and the Horde is kind of a bad / impossible fit. However, I still think compute power wouldn’t be the biggest issue, we can rent that by the hour. And it’s not even hard to set up or that expensive. I think the main issue is coming up with the math and the code to produce something useful. So maybe we need a research community. And these things already happen. I mean the llama.cpp community has long been working on quantization and pioneered some things. There’s people on Reddit discovering new things. We’ve had random(?) individuals contribute substantial advancements to image and vide generation. There have been communities/projects like RedPajama, who trained a model from grounds up (and assembled the dayaset)… Seems very low precision quantization is just a tough nut to crack.
Seems to me Bitnet needs a pile of money in compute, plus a team of bright researchers to improve upon. NanoQuant doesn’t perform as good as any 4bit or 8bit model with a similar resource footprint, so it’d need way more research as well. And RILQ is a bit specific, it’d need further research as well. It’s not entirely clear whether that happens. There’s something like publishing bias. Sometimes researchers don’t publish negative results. So maybe they tried to apply it to lower resolutions, failed, and didn’t write a paper about how they failed. So I’m not sure where to go with this. There isn’t anything we could run or just apply as is.
And the AI Horde does inference with fixed scripts. On something like gaming GPU’s and Apple silicon. People who bought a few old 3090s. But that’s inference only. What’s needed for general research is a new project. It’d need to provide you with cloud GPU, launch Docker containers for arbitrary workloads. And expensive enterprise GPUs, or infiniband clusters of some. So the entire software needs to be scrapped and replaced, and the hardware improved as well for cutting edge research. We maybe can call this new thing AI Horde as well. But it’d be an entirely new thing.
And I guess alignment, harvesting user data and preferences from the user’s interactions could be done as well. At least from the technological perspective. I don’t really know if the audience likes that. Depends a bit on how it’s done.
Apologies for the late reply! Busy days :D
I agree with you. Crowd-sourcing this type of research would be a completely different goal than what the AI Horde was built for, and would probably not be sustainable with part-time / volunteer researchers. Perhaps it’s best for us to just wait until others make more substantial progress.
The goal would still have been inference for the Horde, but with sharing of feedback based on the model’s outputs, to align it more with the original one. However, after considering this approach more, I am afraid that the maths behind it makes it impossible to “reconstruct” the original model’s manifold, or at least capture the same behaviour in all use cases.
I came here to propose this idea because, to the best of my knowledge, this is only LLM community that actually pushes for sharing of resources. However, I have seen a few days ago a post on the LocalLlama community advocating for sharing of OpenCode sessions in order to crowd-source a fine-tuning dataset, so it seems that more people are having the same thoughts! :)
I will keep an eye out on other advancements, and if I actually end up having some time, perhaps I’ll return with some contributions. I agree with you that such a project mostly relies on inference, in which case the AI Horde is not the only one that can provide that capability. What we would need is deploying such a model on HuggingFace, and creating an API endpoint for sharing training data for people that are interested in contributing.
Thanks a lot for offering your thoughts, and taking the time to write such lengthy responses to me! I hope you have a nice weekend!
Have a nice weekend as well!
By the way, in the meantime I rediscovered one of the distributed AI projects I remembered reading about: https://github.com/learning-at-home/hivemind
They have some links to related projects and citations of scientific papers at the bottom.
That is about approaches to both distributed inference, and distributed training.
Oh, I remember this! Thanks for sharing, very nice find! Could be a worthwhile approach once we have the data :)