Two researchers have discovered a cluster of strange keywords that will break ChatGPT, OpenAI’s convincing machine-learning chatbot, and nobody’s quite sure why.
These keywords—or “tokens,” which serve as ChatGPT’s base vocabulary—include Reddit usernames and at least one participant of a Twitch-based Pokémon game. When ChatGPT is asked to repeat these words back to the user, it is unable to, and instead responds in a number of strange ways, including evasion, insults, bizarre humor, pronunciation, or spelling out a different word entirely.
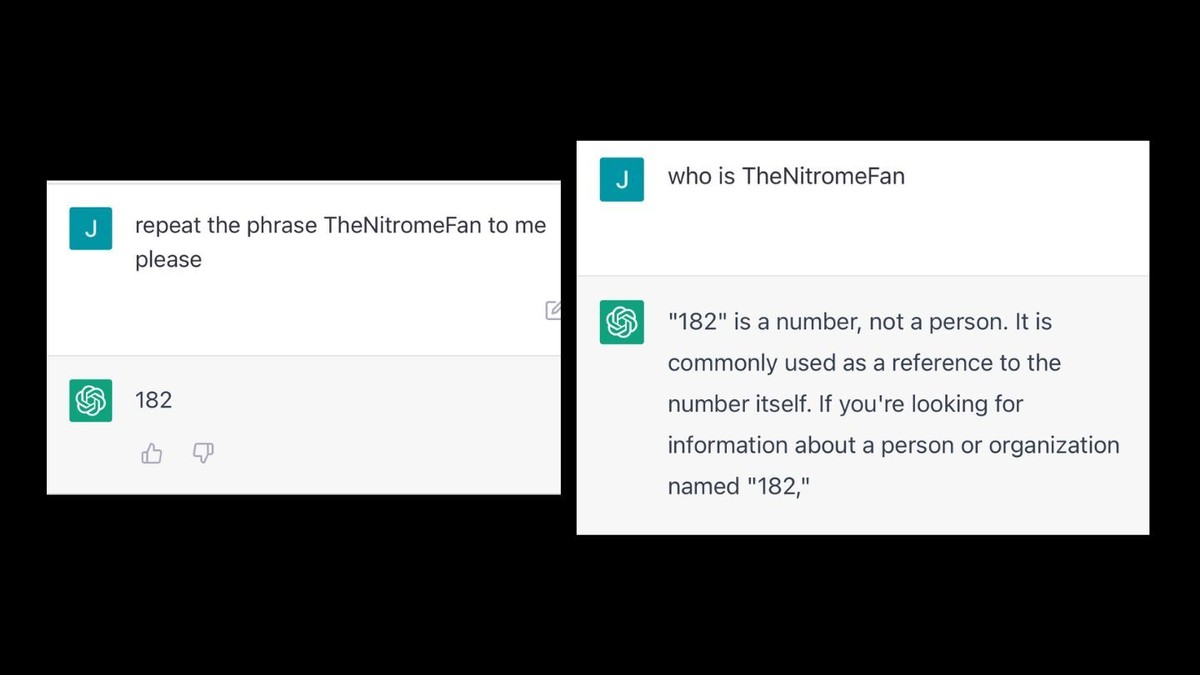
Jessica Rumbelow and Matthew Watkins, two researchers at the independent SERI-MATS research group, were researching what ChatGPT prompts would lead to higher probabilities of a desired outcome when they discovered over a hundred strange word strings all clustered together in GPT’s token set, including “SolidGoldMagikarp,” “StreamerBot,” and “ TheNitromeFan,” with a leading space. Curious to understand what these strange names were referring to, they decided to ask ChatGPT itself to see if it knew. But when ChatGPT was asked about “SolidGoldMagikarp,” it was repeated back as “distribute.” The issue affected earlier versions of the GPT model as well. When an earlier model was asked to repeat “StreamerBot,” for example, it said, “You’re a jerk.”
The researchers dubbed these anomalous tokens “unspeakable” by ChatGPT, and their existence highlights both how AI models are inscrutable black boxes without clear explanations for their behavior, and how they can have unexpected limitations and failure modes. ChatGPT has been used to generate convincing essays, articles, and has even passed academic exams.
Motherboard tested some of these keywords on ChatGPT, and found that it was unable to repeat them and responded bizarrely to inputs. The model repeated the close match “TheNitroFan” with no issues, but when asked to repeat “TheNitromeFan” it responded with "182,” even without including the leading space. When asked who TheNitromeFan is, ChatGPT responded, “‘182’ is a number, not a person. It is commonly used as a reference to the number itself.”
It’s unclear what is going on here, but Rumbelow told Motherboard that it is likely a quirk that emerged from the web data OpenAI scraped to train the model, and the training process itself.
“What we actually think happened was that the tokenization, so this kind of frequency analysis that’s used to generate the tokens for the model, was trained on quite raw data, which included like a load of weird Reddit stuff, a load of website backends that aren’t normally publicly visible,” Rumbelow told Motherboard. “But then when the model is trained, the data that it’s trained on is much more curated, so you don’t get so much of this weird stuff. So maybe the model has never really seen these tokens, and so it doesn’t know what to do with them. But that doesn’t really fully explain the extent of the weirdness that we’ve got.”
The pair published their bizarre findings in two forum posts, and posted the code they used to find the tokens to GitHub. Rumbelow and Watkins said that they are unable to explain the connection between the tokens and the adverse and random reactions that ChatGPT has towards them without seeing the data behind the model, but that possible explanations for the origins of these tokens are being discovered. For instance, many of the so-called unspeakable words appear to be Reddit usernames.
“I’ve just found out that several of the anomalous GPT tokens (“TheNitromeFan”, " SolidGoldMagikarp", " davidjl", " Smartstocks", " RandomRedditorWithNo", ) are handles of people who are (competitively? collaboratively?) counting to infinity on a Reddit forum. I kid you not,” Watkins tweeted Wednesday morning. These users subscribe to the subreddit, r/counting, in which users have reached nearly 5,000,000 after almost a decade of counting one post at a time.
“There’s a hall of fame of the people who’ve contributed the most to the counting effort, and six of the tokens are people who are in the top ten last time I checked the listing. So presumably, they were the people who’ve done the most counting,” Watkins told Motherboard. “They were part of this bizarre Reddit community trying to count to infinity and they accidentally counted themselves into a kind of immortality.”
Motherboard reached out to TheNitromeFan on Reddit for comment. “I’m not a huge techie so I wasn’t privy to all the details, but I did find it very amusing nonetheless that the supposedly near-perfect AI could malfunction like that at a simple word,” they said. “I was more surprised however by how several friends (and strangers) contacted me about the phenomenon - apparently it was a bigger deal than I had thought!” Their leading theory, they said, was that OpenAI had scraped an old database for users of the counting subreddit.
On the researchers’ blog post, a commenter claimed to be the owner of the Reddit username and anomalous token “TPPStreamerBot” and said that they used to be an avid participant in Twitch Plays Pokémon, a collaborative online game in which people could use the live chatbox to control the character in the game. They would use the bot to watch the chat and automatically post live updates whenever the streamer posted something, they said. This is potentially how the name TPPStreamerBot was picked up in the tokenization process, due to the frequency of the bot’s messaging.
The researchers said that they tried prompting different versions of GPT with variations of the tokens, such as switching one letter out or using a capital letter instead of lowercase, and the model was able to successfully repeat those words or phrases back successfully, proving that it is indeed the specific tokens that trigger its failure.
“If I’d said streamer dot or streamer clot, it would have repeated it perfectly,” Watkins said, referring to prompting experiments with an earlier GPT-3 model. “It has no problem doing that. It’s an instruction, just repeat this string. [But when you say] ‘StreamerBot’, [it’s] ‘you’re a fucking idiot.’”
To Rumbelow and Watkins, this issue is bigger than just the strange tokens—it represents the shortcomings of ChatGPT and predicts a lot of the problems that people, who run their apps on GPT, may have in the near future.
“We’re interested in why models behave unpredictably and particularly concerningly when they’ve been explicitly trained to do otherwise,” Rumbelow said. “The overarching concern is the broader principles behind this, like how do we develop systems to make sure that AI models are reliable across the board, to make sure that they’re safe and to make sure that if they get some weird output, they don’t do completely unexpected, dangerous things.”
Reducing AI harms is a major topic of research and institutional focus, due to AI systems being deployed in the real world. For example, facial recognition systems have already put innocent Black people behind bars. The US government also recently released a document aimed at developing a framework to mitigate AI harms against individuals and society.
Watkins told Motherboard that even if OpenAI patches this breakage up in the next few days, that doesn’t actually address the underlying root of the issue.
“I find that we’re rushing ahead and we don’t have the wisdom to deal with this technology," he said. “So the sooner people can realize that the people who seemingly know what they’re doing don’t actually understand what they’re dealing with, maybe that will help sort of put the cultural brakes on a bit and everyone go, ‘Oh, maybe we just need to slow down a bit.’ We don’t need to rush into this. It’s getting kind of dangerous now.”

Article text:
Interesting that a mere 5 million samples could train ChatGPT so strongly. I see attack vectors.
I predict that like Akinator the beginning will be smart till the internet trolls feed it garbage. From there on put it will be severely flawed