
- cross-posted to:
- [email protected]
- [email protected]
- cross-posted to:
- [email protected]
- [email protected]
Back in February of this year you may recall the interesting news that was announced on Phoronix that AMD Quietly Funded A Drop-In CUDA Implementation Built On ROCm: It’s Now Open-Source. That open-source ZLUDA code for AMD GPUs has been available since AMD quit funding the developer earlier this year. But now the code has been retracted. It’s not from NVIDIA legal challenges but rather AMD reversing course on allowing it to be open-source.
As explained in that article earlier in the year, AMD had quietly funded the ZLUDA developer Andrzej Janik to bring his CUDA-compatible implementation to AMD GPUs and atop the ROCm software stack. ZLUDA start off originally as an open-source CUDA implementation for Intel graphics built atop the Level Zero (hence the ZLUDA name) software stack. While working on ZLUDA, he got it working out rather nicely and various CUDA applications running seamlessly on AMD GPUs as shown and benchmarked in my prior article. But then AMD decided to quit funding the project.
The agreement was reportedly that if/when the contract ended, the ZLUDA code could be open-sourced. That’s what happened back in February. But now that code has been retracted from the official public GitHub repository. It’s not from legal threats from NVIDIA as one might imagine given its working to support CUDA on non-NVIDIA hardware, but rather from AMD itself.
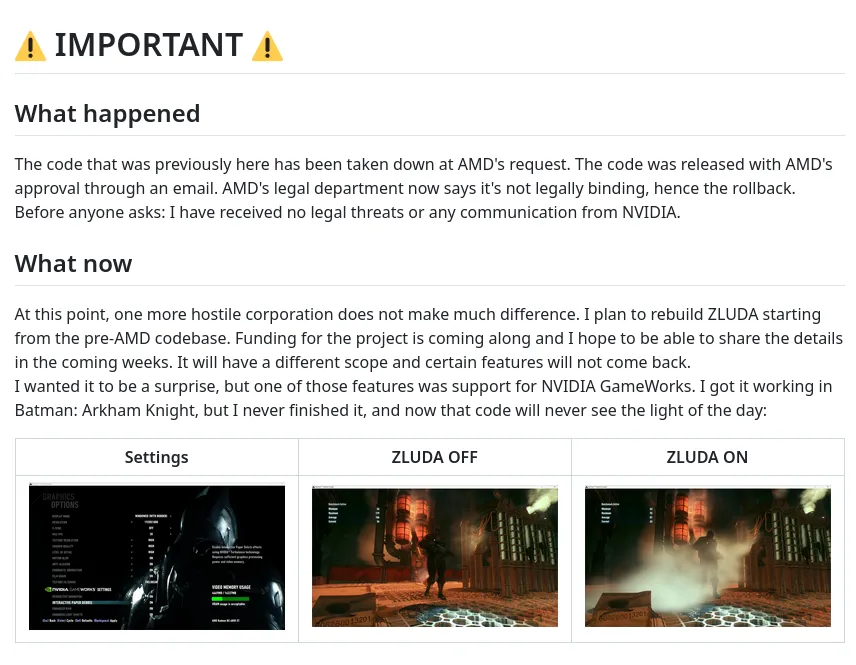
Janik also noted in his announcement that he had a NVIDIA GameWorks implementation working on AMD GPUs but sadly that code will now never be open-sourced.
Andrzej Janik notes he wants to “rebuild ZLUDA” moving forward and is working on project funding. What wasn’t clear from his message whether this means a new ZLUDA focused on the original Intel GPU plans or a new clean sheet design for AMD GPUs. When I asked Janik about it, he’s still exploring options.
It will be very interesting to see where ZLUDA goes from here but disappointing that the prior open-source code has been retracted. The GitHub repository is at vosen/ZLUDA while we are eager to see its future direction.
How I wish CUDA was an open standard. We use it at work, and the tooling is a constant pain. Being almost entirely controlled by NVIDIA, there’s no alternative toolset, and that means little pressure to make it better. Clang being able to compile CUDA code is an encouraging first step, meaning we could possibly do without nvcc. Sadly the CMake support for it on Windows has not yet landed. And that still leaves the SDK and runtime entirely in NVIDIA’s hands.
What irritates me the most about this SDK is the versioning and compatibility madness. Especially on Windows, where the SDK is very picky about the compiler/STL version, and hence won’t allow us to turn on C++20 for CUDA code. I also could never get my head around the backward/forward compatibility between SDK and hardware (let alone drivers).
And the bloat. So many GBs of pre-compiled GPU code for seemingly all possible architectures in the runtime (including cudnn, cublas, etc). I’d be curious about the actual number, but we probably use 1% of this code, yet we have to ship the whole thing, all the time.
If CPU vendors were able to come up with standard architectures, why can’t GPU vendors? So much wasted time, effort, energy, bandwidth, because of this.
How do you people manage this?
Removed by mod