

You already stopped Steven in a prior commit.
Also, if this is an organization setting, I’m extremely disappointed in your PR review process. If someone is committing vendor code to the repo someone else should reject the pull.
What if I told you a lot of companies don’t have solid review requirement processes? Some barely use version control at all
Sure, I understand… but if you’re at one of those companies you should introduce it.
Yeah… Usually if you join a company with bad practices it’s because the people who already work there don’t want to do things properly. They tend to not react well to the new guy telling them what they’re doing wrong.
Only really feasible if you’re the boss, or you have an unreasonable amount of patience.
Usually, the boss (or people above the boss) are the one’s stopping it. Engineers know what the solution is. They may still resent the new guy saying it, though, because they’ve been through this fight already and are tired.
Eh, if everyone knows what they’re doing, it can be much better to not have it and rather do more pairing.
But yes, obviously Steven does not know what they’re doing.
Better to not have version control!? Dear god I hope I never work on anything with you.
Pretty sure they meant to not have review. Dropping peer review in favor of pair programming is a trendy idea these days. Heh, you might call it “pairs over peers”. I don’t agree with it, though. Pair programming is great, but two people, heads together, can easily get on a wavelength and miss the same things. It’s always valuable to have people who have never seen the new changes take a look. Also, peer review helps keep the whole team up to date on their knowledge of the code base, a seriously underrated benefit. But I will concede that trading peer review for pair programming is less wrong than giving up version control. Still wrong, but a lot less wrong.
Agreed. Even self-reviewing a few days after I wrote the code helps me see mistakes.
Well, to share my perspective – sorry, I mean, to explain to you why you’re wrong and differing opinions are unacceptable:
I find that pairing works best for small teams, where everyone is in the loop what everyone else is working on, and which don’t have a bottleneck in terms of a minority having much more skill or knowledge in the project.
In particular, pairing is far more efficient at exchanging information. Not only is it a matter of actively talking to one another just being quicker at bringing information across, there is also a ton of information about code, which will not make it into the actual code.
While coding, you’ve tried two or three approaches, you couldn’t write it as you expected or whatever. The final snippet of code looks as if you wrote it, starting in the top-left and finishing bottom-right, with maybe one or two comments explaining a particularly weird workaround, but I’d wager more than 90% of the creation process is lost.
This means that if someone needs to touch your code, they will know practically none of how it came to be and they will be scared of changing more about it than at all necessary. As a result, all code that gets checked in, needs to be as perfect as possible, right from the start.
Sharing all the information from the creation process by pairing, that empowers a team to write half-baked code. Because enough people know how to finish baking it, or how to restructure it, if a larger problem arises.
Pairing is fickle, though. A bad management decision can easily torpedo it. I’m currently in a project, where we practically cannot pair, because it’s 4 juniors that are new to the project vs. 2 seniors that built up the project.
Not only would we need to pair in groups of three to make that work at all, it also means we need to use the time of the seniors as efficiently as possible and rather waste the time of the juniors, which is where a review process excels at.
Ah, no, I meant a review process. Version control is always a good idea.
Ah, yeah that makes a lot more sense
That’s a big fucking “if”
I’ve seen people trade zip archives like Yo-Ge-oh cards useing excel as a source control manager so it could be much MUCH worse
Dude, put content warnings on this. I have trauma from shared drives and fucking Jared leaving the Important File open on his locked computer while he takes off for a week, locking out access to anyone else.
Those companies probably also pay ABSOLUTE SHITTER
Competence is expensive. Supply is low and demand is high.
Fucking stop Steven, that absolute shitter
Correct me if I’m wrong, but it’s not enough to delete the files in the commit, unless you’re ok with Git tracking the large amount of data that was previously committed. Your git clones will be long, my friend
You’d have to rewrite the history as to never having committed those files in the first place, yes.
And then politely ask all your coworkers to reset their working environments to the “new” head of the branch, same as the old head but not quite.
Chaos ensues. Sirens in the distance wailing.
Rewrite history? Difficult.
Start a new project and nuke the old one? Finger guns.
History is written by the victors. The rest of us have to nuke the project and start over.
If this was committed to a branch would doing a squash merge into another branch and then nuking the old one not do the trick?
Yes, that would do the trick
git clone --depth=1?No, don’t do that. That modifies the commit hashes, so tags no longer work.
git clone --filter=blob:noneis where it’s at.I don’t understand how we’re all using git and it’s not just some backend utility that we all use a sane wrapper for instead.
Everytime you want to do anything with git it’s a weird series or arcane nonsense commands and then someone cuts in saying “oh yeah but that will destroy x y and z, you have to use this other arcane nonsense command that also sounds nothing like you’re trying to do” and you sit there having no idea why either of them even kind of accomplish what you want.
It’s because git is a complex tool to solve complex problems. If you’re one hacker working alone, RCS will do an acceptable job. As soon as you add a second hacker, things change and RCS will quickly show its limitations. FOSS version control went through CVS and SVN before finally arriving at git, and there are good reasons we made each of those transitions. For that matter, CVS and SVN had plenty of arcane stuff to fix weird scenarios, too, and in my subjective experience, git doesn’t pile on appreciably more.
You think deleting an empty directory should be easy? CVS laughs at your effort, puny developer.
It’s because git is a complex tool to solve complex problems. If you’re one hacker working alone, RCS will do an acceptable job. As soon as you add a second hacker, things change and RCS will quickly show its limitations. FOSS version control went through CVS and SVN before finally arriving at git, and there are good reasons we made each of those transitions. For that matter, CVS and SVN had plenty of arcane stuff to fix weird scenarios, too, and in my subjective experience, git doesn’t pile on appreciably more.
Yes it is a complex tool that can solve complex problems, but me as a typical developer, I am not doing anything complex with it, and the CLI surface area that’s exposed to me is by and large nonsense and does not meet me where I’m at or with the commands or naming I would expect.
I mean NPM is also a complex tool, but the CLI surface area of NPM is “npm install”.
I am not doing anything complex with it
So basic, well documented, easily understandable commands like
git add,git commit,git push,git branch, andgit checkoutshould have you covered.the CLI surface area that’s exposed to me is by and large nonsense and does not meet me where I’m at
What an interesting way to say “git has steep learning curve”. Which is true, git takes time to learn and even more to master. You can get there solely by reading the man pages and online docs though, which isn’t something a lot of other complex tools can say (looking at you kubernetes).
Also I don’t know if a package manager really compares in complexity to git, which is not just a version control tool, it’s also a thin interface for manipulating a directed acyclic graph.
So basic, well documented, easily understandable commands like git add, git commit, git push, git branch, and git checkout should have you covered.
You mean:
git add -A,git commit -m "xxx",git pushorgit push -u origin --set-upstream, etc. etc. etc. I get that there’s probably a reason for it’s complexity, but it doesn’t change the fact that it doesn’t just have a steep learning curve, it’s flat out remarkably user unfriendly sometimes.
Well, you’re free to try RCS if you like. It’s still out there.
Git is too hard for you. Please stop using it
There are tons of wrappers for git, but they all kinda suck. They either don’t let you do something the cli does, so you have to resort to the arcane magicks every now and then anyways. Or they just obfuscate things to the point where you have no idea what it’s doing, making it impossible to know how to fix things if (when) it fucks things up.
Git is complicated, but then again, it’s a tool with a lot of options. Could it be nicer and less abstract in its use? Sure!
However, if you compare what goes does, and how it does, to it’s competitors, then git is quite amazing. 5-10 years ago it was all svn, the dark times. Simpler tool and an actual headache to use.
Mercurial is way better.
There, I said it.
I think in this case, “depth” was am inferior solution to achieve fast cloning, that they could quickly implement. Sparse checkout (“filter”) is the good solution that only came out recently-ish
You are not entirely wrong, but just as some advice I would refrain from displaying fear of the command line in interviews.
Lol if an employer can’t have an intelligent discussion about user friendly interface design I’m happy to not work for them.
Every interview I’ve ever been in there’s been some moment where I say ‘yeah I don’t remember that specific command, but conceptually you need to do this and that, if you want I can look up the command’ and they always say something along the lines of ‘oh no, yeah, that makes conceptual sense don’t worry about it, this isn’t a memory test’.
For a lot of experienced people, command line tools are user friendly interface design.
Command line tools can be, git’s interface is not. There would not be million memes about exiting vim if it was.
Thanks, didn’t know about that one.
What are you smoking? Shallow clones don’t modify commit hashes.
The only thing that you lose is history, but that usually isn’t a big deal.
--filter=blob:noneprobably also won’t help too much here since the problem withnode_modulesis more about millions of individual files rather than large files (although both can be annoying).From github’s blog:
git clone --depth=1 <url>creates a shallow clone. These clones truncate the commit history to reduce the clone size. This creates some unexpected behavior issues, limiting which Git commands are possible. These clones also put undue stress on later fetches, so they are strongly discouraged for developer use. They are helpful for some build environments where the repository will be deleted after a single build.Maybe the hashes aren’t different, but the important part is that comparisons beyond the fetched depth don’t work: git can’t know if a shallowly cloned repo has a common ancestor with some given commit outside the range, e.g. a tag.
Blobless clones don’t have that limitation. Git will download a hash+path for each file, but it won’t download the contents, so it still takes much less space and time.
If you want to skip all file data without any limitations, you can do
git clone --filter=tree:0which doesn’t even download the metadataYes, if you ask about a tag on a commit that you don’t have git won’t know about it. You would need to download that history. You also can’t in general say “commit A doesn’t contain commit B” as you don’t know all of the parents.
You are completely right that
--depth=1will omit some data. That is sort of the point but it does have some downsides. Filters also omit some data but often the data will be fetched on demand which can be useful. (But will also cause other issues likeblametaking ridiculous amounts of time.)Neither option is wrong, they just have different tradeoffs.
But that’s my point: instead of things weirdly not working, they will work instead.
See this is the kind of shit that bothers me with Git and we just sort of accept it, because it’s THE STANDARD. And then we crank attach these shitty LFS solutions on the side because it don’t really work.
Give me Perforce, please.
What was perforce’s solution to this? If you delete a file in a new revision, it still kept the old data around, right? Otherwise there’d be no way to rollback.
Yes but Perforce is a (broadly) centralised system, so you don’t end up with the whole history on your local computer. Yes, that then has some challenges (local branches etc, which Perforce mitigates with Streams) and local development (which is mitigated in other ways).
For how most teams work, I’d choose Perforce any day. Git is specialised towards very large, often part time, hyper-distributed development (AKA Linux development), but the reality is that most teams do work with a main branch in a central location.
Yes I’m aware, of course. But then you take on another set of trade-offs. It’s not like shallow cloning SOLVES your problem.
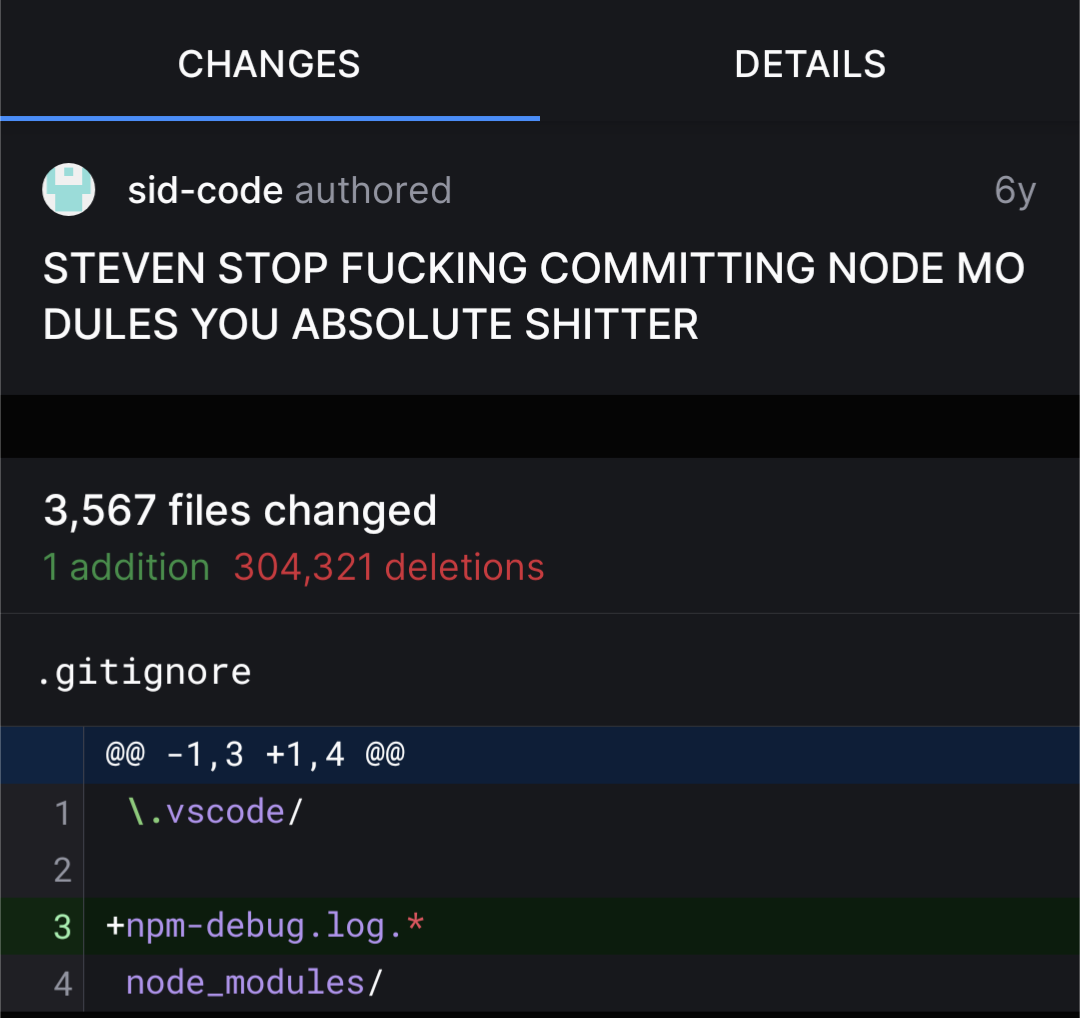
I can’t see past the word wrap implementation in that UI. Mo dules indeed.
Looks like the GitHub android app .
Wow, that’s 300k lines of text that anyone, who clones the repo, has to download.
Do I really have to escape my dots in a
.gitignore?I really don’t think so. The documentation says nothing of the like.
Maybe someone thought it’s a regex pattern, where escaping dots would make sense. But yeah, it mostly works like glob patterns instead.
nah
Not usually
Also don’t need trailing slash
Why do I get the feeling this is Steven’s commit?
sid-codesteven is dumb-code
Creating a mucj larger dl. What a dick.
deleted by creator
He assumed it was like a compile step.
Once you push it once it is pretty fast.










{kind=link}