

It’s so funny how all this is only a problem within a capitalist frame of reference.
What they call “AI” is only “intelligent” within a capitalist frame of reference, too.
I don’t understand why you’re being downvoted. Current “AI” based on LLM’s have no capacity for understanding of the knowledge they contain (hence all the “hallucinations”), and thus possess no meaningful intelligence. To call it intelligent is purely marketing.
Oh no!
Anyway…
I’ve been hearing about the imminent crash for the last two years. New money keeps getting injected into the system. The bubble can’t deflate while both the public and private sector have an unlimited lung capacity to keep puffing into it. FFS, bitcoin is on a tear right now, just because Trump won the election.
This bullshit isn’t going away. Its only going to get forced down our throats harder and harder, until we swallow or choke on it.
With the right level of Government support, bubbles can seemingly go on for literal decades. Case in point, Australian housing since the late 90s has been on an uninterrupted tear (yes, even in ‘08 and ‘20).
But eventually, bubbles either deflate or pop, because eventually governments and investors will get tired of propping it up. It might take decades, but I think it’s inevitable.
Thank fuck. Can we have cheaper graphics cards again please?
I’m sure a RTX 4090 is very impressive, but it’s not £1800 impressive.
Just wait for the 5090 prices…
I just don’t get whey they’re so desperate to cripple the low end cards.
Like I’m sure the low RAM and speed is fine at 1080p, but my brother in Christ it is 2024. 4K displays have been standard for a decade. I’m not sure when PC gamers went from “behold thine might from thou potato boxes” to “I guess I’ll play at 1080p with upscaling if I can have a nice reflection”.
4k displays are not at all standard and certainly not for a decade. 1440p is. And it hasn’t been that long since the market share of 1440p overtook that of 1080p according to the Steam Hardware survey IIRC.
Maybe not monitors, but certainly they are standard for TVs (which are now just monitors with Android TV and a tuner built in).
That doesn’t really matter if people on PC don’t game on it, does it?
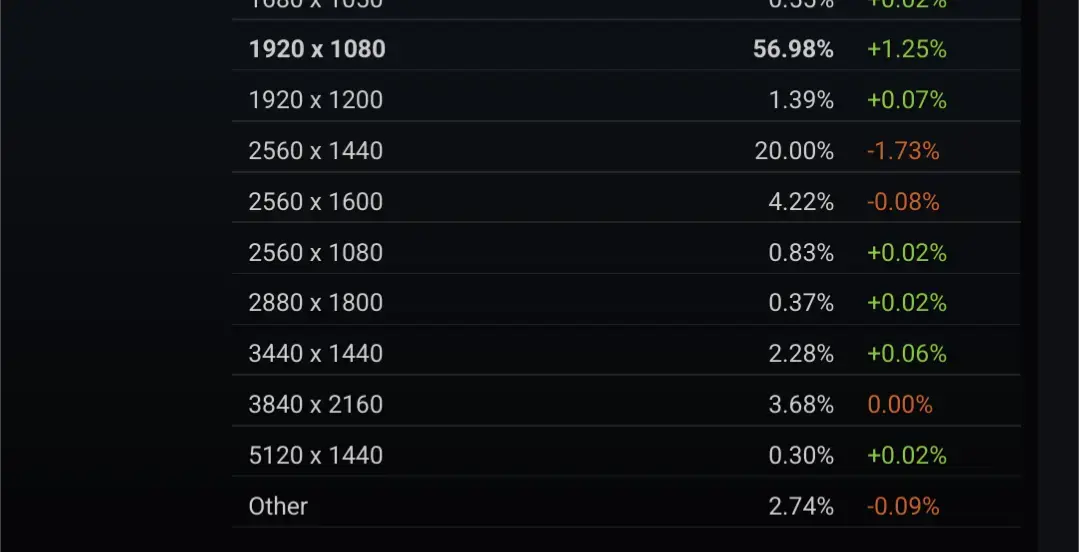
These are the primary display resolutions from the Steam Hardware Survey.
I do wonder how much higher that would be if GPUs targeting 4K were £299 rather than £999.
Although some of it is down to monitors being on desks right in front of you and 4K not really being needed. It would also be interesting to for Valve to weight the results by hours spent gaming that month (and amount they actually spend on games), rather than just counting hardware numbers.
You’re so close to the answer. Now, why are PC gamers the ones still on 1080 and 1440 when everyone else has moved on?
Have I said anything in favor of crippling lower end cards or that these high prices of the high end cards are good? My only argument was that 4K displays in the PC space being the standard was simply delusional because the stats say something wholly different.
Well, people aren’t sticking 4090s in their Samsung smart TVs, so idk that matters.
I think it’s just an upselling strategy, although I agree I don’t think it makes much sense. Budget gamers really should look to AMD these days, but unfortunately Nvidia’s brand power is ridiculous.
An the issue for PC gamers is that Nvidia has spent the last few years convincing devs to shovel DLSS into everything, rather than a generic upscaling solution that other vendors could just drop their own algorithms into, meaning there’s a ton of games that won’t upscale nicely on anything else.
Before you claim 4k is the standard, you might wanna take a peak at the Steam hardware survey.
I don’t know anyone I game with that uses a 4k monitor. 1440p at your monitors max refresh rate is the favorite.
Sorry, crypto is back in season.
nope, if normal gamers are already willing to pay that price, no reason for nvidia to reduce them.
There’s more 4090 on steam than any AMD dedicated GPU, there’s no competition
I swapped to AMD this generation and it’s still expensive.
A well researched pre-owned is the way to go. I bought a 6900xt a couple years ago for a deal.
I used to buy broken video cards on ebay for ~$25-50. The ones that run, but shut off have clogged heat sinks. No tools or parts required. Just blow out the dust. Obviously more risky, but sometimes you can hit gold.
If you can buy a ten and one works, you’ve saved money. Two work and you’re making money. The only question is whether the tenth card really will work or not.
And are you really interested in selling the extras?
For the price of the bundle? Sure.
Really? I’m far too lazy to list things like that. If I was, I’d be buying a lot more than 10 and make a little business out of it.
Graphics cards are so bulky nowadays it’s often hard to even fit two on one mobo, as much as I’d love to see 10 GPUs all linked up.
Lol. I guess you’d need to go to a mining crypto den then, I hear they pull that sort of nonsense. ;)
But seriously though, I’m not interested in listing, shipping, and dealing w/ customer feedback just to save a few bucks on a GPU, because that sounds like a job.
I used to get EVGA bstock which was reasonable but they got out of the business 😞
AMD will go back to the same strategy they had with the RX 580. They don’t plan to release high end cards next generation. It seems they just want to pump out a higher volume of mid-tier (which is vague and subjective) while fixing hardware bugs plaguing the previous generation.
Hopefully, this means we can game on a budget while AMD is focusing primarily on marketshare.
I work with people who work in this field. Everyone knows this, but there’s also an increased effort in improvements all across the stack, not just the final LLM. I personally suspect the current generation of LLMs is at its peak, but with each breakthrough the technology will climb again.
Put differently, I still suspect LLMs will be at least twice as good in 10 years.
The hype should go the other way. Instead of bigger and bigger models that do more and more - have smaller models that are just as effective. Get them onto personal computers; get them onto phones; get them onto Arduino minis that cost $20 - and then have those models be as good as the big LLMs and Image gen programs.
Other than with language models, this has already happened: Take a look at apps such as Merlin Bird ID (identifies birds fairly well by sound and somewhat okay visually), WhoBird (identifies birds by sound, ) Seek (visually identifies plants, fungi, insects, and animals). All of them work offline. IMO these are much better uses of ML than spammer-friendly text generation.
those are all classification problems, which is a fundamentally different kind of problem with less open-ended solutions, so it’s not surprising that they are easier to train and deploy.
Platnet and iNaturalist are pretty good for plant identification as well, I use them all the time to find out what’s volunteering in my garden. Just looked them up and it turns out iNaturalist is by Seek.
This has already started to happen. The new llama3.2 model is only 3.7GB and it WAAAAY faster than anything else. It can thow a wall of text at you in just a couple of seconds. You’re still not running it on $20 hardware, but you no longer need a 3090 to have something useful.
Well, you see, that’s the really hard part of LLMs. Getting good results is a direct function of the size of the model. The bigger the model, the more effective it can be at its task. However, there’s something called compute efficient frontier (technical but neatly explained video about it). Basically you can’t make a model more effective at their computations beyond said linear boundary for any given size. The only way to make a model better, is to make it larger (what most mega corps have been doing) or radically change the algorithms and method underlying the model. But the latter has been proving to be extraordinarily hard. Mostly because to understand what is going on inside the model you need to think in rather abstract and esoteric mathematical principles that bend your mind backwards. You can compress an already trained model to run on smaller hardware. But to train them, you still need the humongously large datasets and power hungry processing. This is compounded by the fact that larger and larger models are ever more expensive while providing rapidly diminishing returns. Oh, and we are quickly running out of quality usable data, so shoveling more data after a certain point starts to actually provide worse results unless you dedicate thousands of hours of human labor producing, collecting and cleaning the new data. That’s all even before you have to address data poisoning, where previously LLM generated data is fed back to train a model but it is very hard to prevent it from devolving into incoherence after a couple of generations.
this is learning completely the wrong lesson. it has been well-known for a long time and very well demonstrated that smaller models trained on better-curated data can outperform larger ones trained using brute force “scaling”. this idea that “bigger is better” needs to die, quickly, or else we’re headed towards not only an AI winter but an even worse climate catastrophe as the energy requirements of AI inference on huge models obliterate progress on decarbonization overall.
That would be innovation, which I’m convinced no company can do anymore.
It feels like I learn that one of our modern innovations was already thought up and written down into a book in the 1950s, and just wasn’t possible at that time due to some limitation in memory, precision, or some other metric. All we did was do 5 decades of marginal improvement to get to it, while not innovating much at all.
Are you talking about something specific?
Welcome to the top of the sigmoid curve.
If you were wondering what 1999 felt like WRT to the internet, well, here we are. The Matrix was still fresh in everyone’s mind and a lot of online tech innovation kinda plateaued, followed by some “market adjustments.”
I think it’s more likely a compound sigmoid (don’t Google that). LLMs are composed of distinct technologies working together. As we’ve reached the inflection point of the scaling for one, we’ve pivoted implementations to get back on track. Notably, context windows are no longer an issue. But the most recent pivot came just this week, allowing for a huge jump in performance. There are more promising stepping stones coming into view. Is the exponential curve just a series of sigmoids stacked too close together? In any case, the article’s correct - just adding more compute to the same exact implementation hasn’t enabled scaling exponentially.
I think I’ve heard about enough of experts predicting the future lately.
I just want a portable self hosted LLM for specific tasks like programming or language learning.
You can install Ollama in a docker container and use that to install models to run locally. Some are really small and still pretty effective, like Llama 3.2 is only 3B and some are as little as 1B. It can be accessed through the terminal or you can use something like OpenWeb UI to have a more “ChatGPT” like interface.
I have a few LLMs running locally. I don’t have an array of 4090s to spare so I am limited to the smaller models 8B and whatnot.
They definitely aren’t as good as anything you get remotely. It’s more private and controlled but it’s much less useful (I’ve found) than any of the other models.
Marcus is right, incremental improvements in AIs like ChatGPT will not lead to AGI and were never on that course to begin with. What LLMs do is fundamentally not “intelligence”, they just imitate human response based on existing human-generated content. This can produce usable results, but not because the LLM has any understanding of the question. Since the current AI surge is based almost entirely on LLMs, the delusion that the industry will soon achieve AGI is doomed to fall apart - but not until a lot of smart speculators have gotten in and out and made a pile of money.
I hope it all burns.
This is why you’re seeing news articles from Sam Altman saying that AGI will blow past us without any societal impact. He’s trying to lessen the blow of the bubble bursting for AI/ML.
Short on the AI stocks before it crash!
The market can remain irrational longer than you can remain solvent.
A. Gary Shilling
Oh nice, another Gary Marcus “AI hitting a wall post.”
Like his “Deep Learning Is Hitting a Wall” post on March 10th, 2022.
Indeed, not much has changed in the world of deep learning between spring 2022 and now.
No new model releases.
No leaps beyond what was expected.
\s
Gary Marcus is like a reverse Cassandra.
Consistently wrong, and yet regularly listened to, amplified, and believed.
It’s been 5 minutes since the new thing did a new thing. Is it the end?
As I use copilot to write software, I have a hard time seeing how it’ll get better than it already is. The fundamental problem of all machine learning is that the training data has to be good enough to solve the problem. So the problems I run into make sense, like:
- Copilot can’t read my mind and figure out what I’m trying to do.
- I’m working on an uncommon problem where the typical solutions don’t work
- Copilot is unable to tell when it doesn’t “know” the answer, because of course it’s just simulating communication and doesn’t really know anything.
2 and 3 could be alleviated, but probably not solved completely with more and better data or engineering changes - but obviously AI developers started by training the models on the most useful data and strategies that they think work best. 1 seems fundamentally unsolvable.
I think there could be some more advances in finding more and better use cases, but I’m a pessimist when it comes to any serious advances in the underlying technology.
Not copilot, but I run into a fourth problem:
4. The LLM gets hung up on insisting that a newer feature of the language I’m using is wrong and keeps focusing on “fixing” it, even though it has access to the newest correct specifications where the feature is explicitly defined and explained.I’ve also run into this when trying to program in Rust. It just says that the newest features don’t exist and keeps rolling back to an unsupported library.
Oh god yes, ran into this asking for a shell.nix file with a handful of tricky dependencies. It kept trying to do this insanely complicated temporary pull and build from git instead of just a 6 line file asking for the right packages.
“This code is giving me a return value of X instead of Y”
“Ah the reason you’re having trouble is because you initialized this list with brackets instead of
new().”“How would a syntax error give me an incorrect return”
“You’re right, thanks for correcting me!”
“Ok so like… The problem though.”
Yeah, once you have to question its answer, it’s all over. It got stuck and gave you the next best answer in it’s weights which was absolutely wrong.
You can always restart the convo, re-insert the code and say what’s wrong in a slightly different way and hope the random noise generator leads it down a better path :)
I’m doing some stuff with translation now, and I’m finding you can restart the session, run the same prompt and get better or worse versions of a translation. After a few runs, you can take all the output and ask it to rank each translation on correctness and critique them. I’m still not completely happy with the output, but it does seem that sometime if you MUST get AI to answer the question, there can be value in making it answer it across more than one session.
- Copilot can’t read my mind and figure out what I’m trying to do.
Try writing comments
So you use other people’s open source code without crediting the authors or respecting their license conditions? Good for you, parasite.
Very frequently, yes. As well as closed source code and intellectual property of all kinds. Anyone who tells you otherwise is a liar.
Ah, I guess I’ll have to question why I am lying to myself then. Don’t be a douchebag. Don’t use open source without respecting copyrights & licenses. The authors are already providing their work for free. Don’t shit on that legacy.
I completely understand where you’re coming from, and I absolutely agree with you, genAI is copyright infringement on a weapons-grade scale. With that said, though, in my opinion, I don’t know if calling people parasites like this will really convince people, or change anything. I don’t want to tone police you, if you want to tell people to get fucked, then go ahead, but I think being a bit more sympathetic to your fellow programmers and actually trying to help them see things from our perspective might actually change some minds. Just something to think about. I don’t have all the answers, feel free to ignore me. Much love!
You are right. My apologies, and my congratulations for finding the correct “tone” to respond to me ;) The thing is, I am absolutely fed up with especially the bullshit about snake oil vendors selling LLMs as “AI”, and I am much more fed up with corporations on a large scale getting away with - since it’s for profit - what I guess must already be called theft of intellectual property.
When people then use said LLMs to “develop software”, I’m kind of convinced they are about as gone mentally as the MAGA cult and sometimes I just want to vent. However, I chose the word parasite for a reason, because it’s a parasitic way of working: they use the work of other people, which for more specific algorithms, an LLM will reproduce more or less verbatim, while causing harm to such people by basically copy-pasting such code while omitting the license statement - thereby releasing such code (if open source) into the “wild” with an illegally(*) modified license.
- illegal of course only in such countries whose legal system respects copyright and license texts in the first place
Considering on top the damage done to the environment by the insane energy consumption for little to no gain, people should not be using LLMs at all. Not even outside coding. This is just another way to contribute missing our climate goals by a wide margin. Wasting energy like this - basically because people are too lazy to think for themselves - actually gets people killed due to extreme weather events.
So yeah, you have a valid point, but also, I am fed up with the egocentric bullshit world that social media has created and that has culminated in what will soon be a totalitarian regime in the country that once brought peace to Europe by defeating the Nazis and doing a PROPER reeducation of the people. Hooray for going off on a tangent…
Programmers don’t have the luxury of using inferior toolsets.
That statement is as dumb as it is non-sensical.
Ahh right, so when I use copilot to autocomplete the creation of more tests in exactly the same style of the tests I manually created with my own conscious thought, you’re saying that it’s really just copying what someone else wrote? If you really believe that, then you clearly don’t understand how LLMs work.
I know both LLM mechanisms better than you, it would appear, and my point is not so weak that I would have to fabricate a strawman that I then claim is what you said, to proceed to argue the strawman.
Using LLMs trained on other people’s source code is parasitic behaviour and violates copyrights and licenses.
Look, I recognize that it’s possible for LLMs to produce code that is literally someone else’s copyrighted code. However, the way I use copilot is almost exclusively to autocomplete my thoughts. Like, I write enough code until it guesses what I was about to write next. If that happens to be open source code that someone else has written, then it is complete coincidence that I thought of writing that code. Not all thoughts are original.
Further, whether I should be at fault for LLM vendors who may be breaking copyright law, is like trying to make a case for me being at fault for murder because I drive a car when car manufacturers lobby to the effect that people die more.
Not all thoughts are original.
Agreed, and I am also 100% opposed to SW patents. No matter what I wrote, if someone came up with the same idea on their own, and finds out about my implementation later, I absolutely do not expect them to credit me. In the use case you describe, I do not see a problem of using other people’s work in a license breaking way. I do however see a waste of time - you have to triple check everything an LLM spits out - and energy (ref: MS trying to buy / restart a nuclear reactor to power their LLM hardware).
Further, whether I should be at fault for LLM vendors who may be breaking copyright law, is like trying to make a case for me being at fault for murder because I drive a car when car manufacturers lobby to the effect that people die more.
If you drive a car on “autopilot” and get someone killed, you are absolutely at fault for murder. Not in the legal sense, because fuck capitalism, but absolutely in the moral sense. Also, there’s legal precedent in a different example: https://www.findlaw.com/legalblogs/criminal-defense/can-you-get-arrested-for-buying-stolen-goods/
If you unknowingly buy stolen (fenced) goods, if found out, you will have to return them to the rightful owner without getting your money back - that you would then have to try and get back from the vendor.
In the case of license agreements, you would still be participant to a license violation - and if you consider a piece of code that would be well-recognizable, just think about the following thought experiment:
Assume someone trained the LLM on some source code Disney uses for whatever. Your code gets autocompleted with that and you publish it, and Disney finds out about it. Do you honestly think that the evil motherfuckers at Disney would stop at anything short of having your head served on a silver platter?






