

- cross-posted to:
- [email protected]
- cross-posted to:
- [email protected]
Alright, show me I’m not the only one in this community, and show off some solutions!
Here’s my Day 1 solution in Factor (minus imports):
spoiler
: get-input ( -- left-list right-list )
"aoc-2024.01" "input.txt" vocab-file-lines
[ split-words harvest ] map unzip
[ [ string>number ] map ] bi@ ;
: part1 ( -- n )
get-input
[ sort ] bi@
[ - abs ] 2map-sum ;
: part2 ( -- n )
get-input
histogram
'[ dup _ at 0 or * ] map-sum ;
Sadly, Factor doesn’t get highlighted properly here, so here it is again as an image:
spoiler

I probably won’t last the week, but what solutions I do have will be up on GitHub.
You must log in or register to comment.
More Factor solutions for the first 3 days (at time of comment) from okflo, on sourcehut.
Day 3
spoiler
: get-input ( -- corrupted-input ) "aoc-2024.03" "input.txt" vocab-file-path utf8 file-contents ; : get-muls ( corrupted-input -- instructions ) R/ mul\(\d+,\d+\)/ all-matching-subseqs ; : process-mul ( instruction -- n ) R/ \d+/ all-matching-subseqs [ string>number ] map-product ; : solve ( corrupted-input -- n ) get-muls [ process-mul ] map-sum ; : part1 ( -- n ) get-input solve ; : part2 ( -- n ) get-input R/ don't\(\)(.|\n)*?do\(\)/ split concat R/ don't\(\)(.|\n)*/ "" re-replace solve ;Image:
spoiler

Some more Factor solutions for the first 3 days (so far) from soweli Niko, on Codeberg.
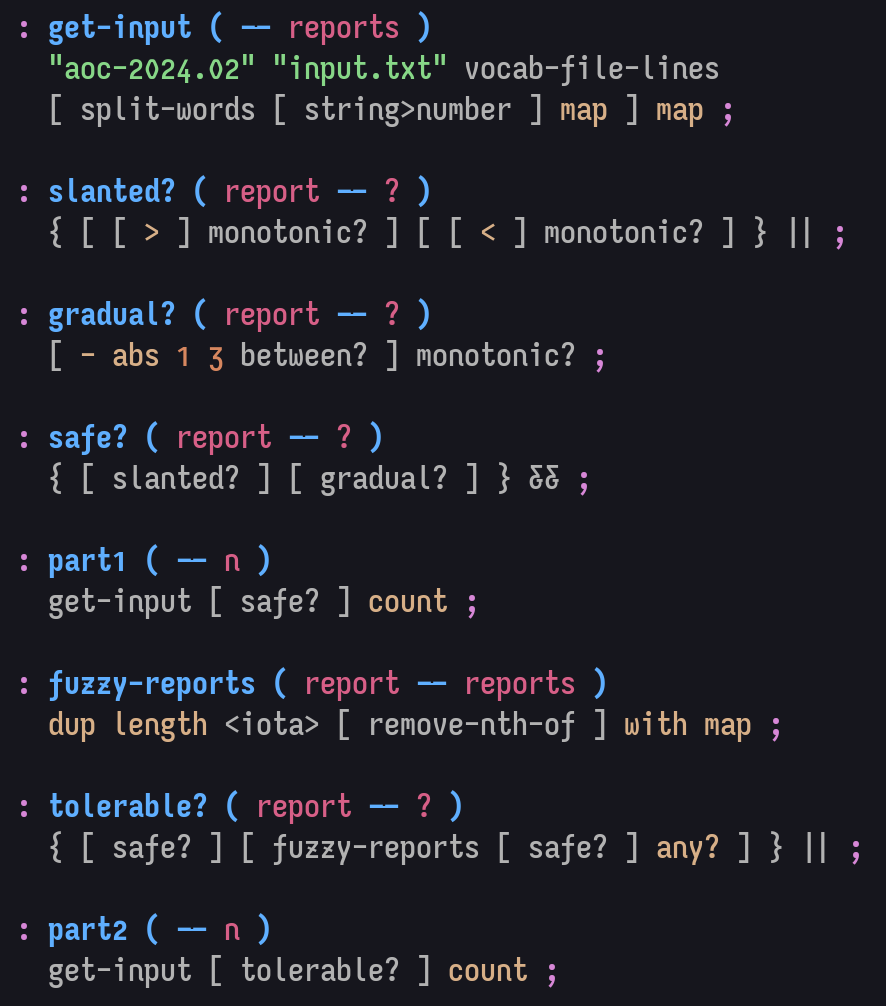
Day 2:
spoiler
: get-input ( -- reports ) "aoc-2024.02" "input.txt" vocab-file-lines [ split-words [ string>number ] map ] map ; : slanted? ( report -- ? ) { [ [ > ] monotonic? ] [ [ < ] monotonic? ] } || ; : gradual? ( report -- ? ) [ - abs 1 3 between? ] monotonic? ; : safe? ( report -- ? ) { [ slanted? ] [ gradual? ] } && ; : part1 ( -- n ) get-input [ safe? ] count ; : fuzzy-reports ( report -- reports ) dup length <iota> [ remove-nth-of ] with map ; : tolerable? ( report -- ? ) { [ safe? ] [ fuzzy-reports [ safe? ] any? ] } || ; : part2 ( -- n ) get-input [ tolerable? ] count ;Image:
spoiler
Day 5
spoiler
: get-input ( -- rules updates ) "vocab:aoc-2024/05/input.txt" utf8 file-lines { "" } split1 "|" "," [ '[ [ _ split ] map ] ] bi@ bi* ; : relevant-rules ( rules update -- rules' ) '[ [ _ in? ] all? ] filter ; : compliant? ( rules update -- ? ) [ relevant-rules ] keep-under [ [ index* ] with map first2 < ] with all? ; : middle-number ( update -- n ) dup length 2 /i nth-of string>number ; : part1 ( -- n ) get-input [ compliant? ] with [ middle-number ] filter-map sum ; : compare-pages ( rules page1 page2 -- <=> ) [ 2array relevant-rules ] keep-under [ drop +eq+ ] [ first index zero? +gt+ +lt+ ? ] if-empty ; : correct-update ( rules update -- update' ) [ swapd compare-pages ] with sort-with ; : part2 ( -- n ) get-input dupd [ compliant? ] with reject [ correct-update middle-number ] with map-sum ;Day 4
spoiler
: get-input ( -- rows ) "vocab:aoc-2024/04/input.txt" utf8 file-lines ; : verticals ( rows -- lines ) [ dimension last [0..b) ] keep cols ; : slash-origins ( rows -- coords ) dimension [ first [0..b) [ 0 2array ] map ] [ first2 [ 1 - ] [ 1 (a..b] ] bi* [ 2array ] with map ] bi append ; : backslash-origins ( rows -- coords ) dimension first2 [ [0..b) [ 0 2array ] map ] [ 1 (a..b] [ 0 swap 2array ] map ] bi* append ; : slash ( rows origin -- line ) first2 [ 0 [a..b] ] [ pick dimension last [a..b) ] bi* zip swap matrix-nths ; : backslash ( rows origin -- line ) [ dup dimension ] dip first2 [ over first [a..b) ] [ pick last [a..b) ] bi* zip nip swap matrix-nths ; : slashes ( rows -- lines ) dup slash-origins [ slash ] with map ; : backslashes ( rows -- lines ) dup backslash-origins [ backslash ] with map ; : word-count ( line word -- n ) dupd [ reverse ] dip '[ _ subseq-indices length ] bi@ + ; : part1 ( -- n ) get-input { [ ] [ verticals ] [ slashes ] [ backslashes ] } cleave-array concat [ "XMAS" word-count ] map-sum ; : origin-adistances ( rows origins line-quot: ( rows origin -- line ) -- origin-adistances-assoc ) with zip-with "MAS" "SAM" [ '[ [ _ subseq-indices ] map-values ] ] bi@ bi append harvest-values [ [ 1 + ] map ] map-values ; inline : a-coords ( origin-adistances coord-quot: ( adistance -- row-delta col-delta ) -- coords ) '[ first2 [ @ 2array v+ ] with map ] map-concat ; inline : slash-a-coords ( rows -- coords ) dup slash-origins [ slash ] origin-adistances [ [ 0 swap - ] keep ] a-coords ; : backslash-a-coords ( rows -- coords ) dup backslash-origins [ backslash ] origin-adistances [ dup ] a-coords ; : part2 ( -- n ) get-input [ slash-a-coords ] [ backslash-a-coords ] bi intersect length ;Better viewed on GitHub
Day 6
spoiler
: get-input ( -- rows ) "vocab:aoc-2024/06/input.txt" utf8 file-lines ; : all-locations ( rows -- pairs ) dimension <coordinate-matrix> concat ; : guard-location ( rows -- pair ) [ all-locations ] keep '[ _ matrix-nth "<>^v" in? ] find nip ; TUPLE: state location char ; C: <state> state : guard-state ( rows -- state ) [ guard-location ] [ dupd matrix-nth ] bi <state> ; : faced-location ( state -- pair ) [ char>> H{ { CHAR: > { 0 1 } } { CHAR: v { 1 0 } } { CHAR: < { 0 -1 } } { CHAR: ^ { -1 0 } } } at ] [ location>> ] bi v+ ; : off-grid? ( rows location -- ? ) [ dimension ] dip [ v<= vany? ] keep { 0 0 } v< vany? or ; : turn ( state -- state' ) [ location>> ] [ char>> ] bi H{ { CHAR: > CHAR: v } { CHAR: v CHAR: < } { CHAR: < CHAR: ^ } { CHAR: ^ CHAR: > } } at <state> ; : obstacle? ( rows location -- ? ) swap matrix-nth CHAR: # = ; : guard-step ( rows state -- state' ) swap over faced-location { { [ 2dup off-grid? ] [ 2nip f <state> ] } { [ [ obstacle? ] keep-under ] [ drop turn ] } [ swap char>> <state> ] } cond ; : walk-out ( rows state -- trail ) [ [ 2dup location>> off-grid? ] [ dup location>> , dupd guard-step ] until ] { } make 2nip ; : part1 ( -- n ) get-input dup guard-state walk-out cardinality ; : (walk-loops?) ( visited rows state -- looped? ) dupd guard-step 2dup location>> off-grid? [ 3drop f ] [ pick dupd in? [ 3drop t ] [ pick dupd adjoin (walk-loops?) ] if ] if ; : walk-loops? ( rows -- looped? ) dup guard-state [ HS{ } clone ] 2dip pick dupd adjoin (walk-loops?) ; : obstacle-candidates ( rows -- pairs ) [ guard-location ] [ dup guard-state walk-out members ] bi remove ; : part2 ( -- n ) get-input dup obstacle-candidates [ CHAR: # spin deep-clone [ matrix-set-nth ] keep walk-loops? ] with count ;