
{kind=link}
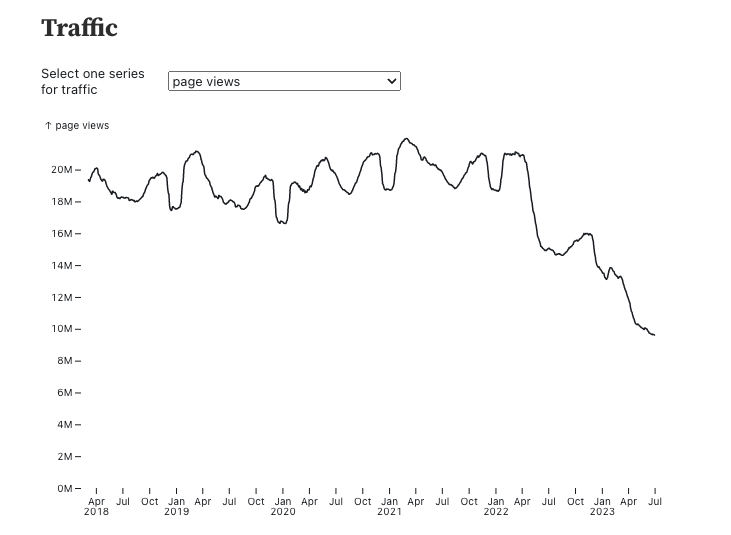
Stack Overflow has seen a substantial decline in traffic over the last year that appears to be accelerating. https://observablehq.com/@ayhanfuat/the-fall-of-stack-overflow
Stack Overflow has seen a substantial decline in traffic over the last year that appears to be accelerating. https://observablehq.com/@ayhanfuat/the-fall-of-stack-overflow
Most of the comments here seem to be arguing whether it’s better to get help now from SO or ChatGPT, but this is a pretty short-sighted mindset.
What happens when the next new standard comes out that ChatGPT hasn’t been trained on? If SO tanks and dies, where will you go?
I’m not saying use a lesser resource, I’m saying this is kinda tragic and I hope they can sustain themselves; AI is propped up by human input and can’t train itself.
Does it really though? It seems to me that once you nail the general intelligence, you’ll just need to provide the supplemental information (e.g. new documentations) for it to give an accurate response.
Bing already somewhat does this by connecting their bot to internet searches
We’re not able to properly define general intelligence, let alone build something that qualifies as intelligent.
I can think of four aspects needed to emulate human response: basic knowledge on various topics, logical reasoning, contextual memory, and ability to communicate; and ChatGPT seems to possess all four to a certain degree.
Regardless of what you think is or isn’t intelligent, for programming help you just need something to go through tons of text and present the information most likely to help you, maybe modify it a little to fit your context. That doesn’t sound too far fetched considering what we have today and how much information are available on the internet
LLM’s cannot reason, nor can they communicate. They can give the illusion of doing so, and that’s if they have enough data in the domain you’re prompting them with. Try to go into topics that aren’t as popular on the internet, the illusion breaks down pretty quickly. This isn’t “we’re not there yet”, it’s a fundamental limitation of the technology. LLM’s are designed to mimick the style of a human response, they don’t have any logical capabilities.
You’re the one who brought up general intelligence not me, but to respond to your point: The problem is that people had an incentive to contribute that text, and it wasn’t necessarily monetary. Whether it was for internet points or just building a reputation, people got something in return for their time. With LLM’s, that incentive is gone, because no matter what they contribute it’s going to be fed to a model that won’t attribute those contributions back to them.
Today LLM’s are impressive because they use information that was contributed by millions of people. The more people rely on ChatGPT, the less information will be available to train it on, and the less impressive these models are going to be over time.
deleted by creator
What if the documentation is lacking? Experienced users will still know how a library works because they’ve tried some things, but that information won’t be available if they never talk about it online
how do people still have this much faith in the tools humans build after seeing the climate change caused by the industrial revolution.
I was working on a hobby project where I used a niche framework in a somewhat uncommon way. I was stuck on a concept that I think the documentation didn’t explain well enough, at least for me, and I couldn’t find any resource on it aside from the docs.
I asked Bing to write a piece of code that does what I wanted and explain each line. It was perfectly working and the explanation was also understandable. All it did was search for its official documentation. It really blew my mind.
deleted by creator
We will go to the documentation.
Oh god, oh no.
Do you realize what that will mean? My coworkers will have to learn how to understand documentation standards that rely on anything but “self documenting code.”
I am already “an expert (lol @ my salary)” because I read shit they don’t bother looking up. We’re truly doomed.
That’s a pipe dream thinking all the documentation is complete and well detailed
I can’t count the times where I read the documentation for the tutorial to get started and the steps described in the official documentation by the official maintainer fails early.
Documentation is 99% an afterthought (slight exaggeration here)
Hey, if people are going to go back to reading manuals like we’re in the 1980’s again is it such a bad thing? /s
It’s insane how a single tool managed to completely destroy the value collectively created by people in over a decade.
That single tool is still propped up by that collective decade of knowledge. ChatGPT would be nothing without sites like stackoverflow
Yeah but will people still care about contributing that information if they’re not going to be compensated for it in any way? Like people get something out of contributing to stack overflow, even if it’s just recognition. This is gone with ChatGPT.
Isn’t that the FOSS model since ever?
With the FOSS model you get credited at least, so you are getting something out of it even if it’s not monetary. With ChatGPT you don’t even get that. You’re feeding an AI that’s being monetized by someone else, what possible incentive could people have to contribute anymore?
Not everyone is motivated by money and recognition, are you aware of that? Since humans were humans, cooperation has been an integral part of society and still is today.
Some people will always try to monetize everything, but still, people continue to develop FOSS.
ChatGPT will be no different in that regard.
When a single entity reaps all of the rewards of that cooperation, people are much less motivated to do that.
Some people are politically motivated, there are tons of reasons, but it’s a two way interaction in all of these cases.
Crazy idea, what about a “federated” search. Hook up the websites’ internal search engines to an aggregator. Stop allowing random indexing spiders to scrape.
very good point! I find myself using ChatGPT more for references and I am also afraid what will happen if there isn’t enough “human generated content” to train on. I can picture an edge case a chunk of the internet is AI generated content (with even users at the wheel). The the next wave of AI will train on previous gen AI output
We go back to expertsexchange
AI should be trained by itself though. I just wouldn’t call LLMs “AI” as a term
Also, it shall be possible in the future to just feed it the documentation and have answers. Obviously we are still nowhere near yet